Как нас обманывают через бенчмарки
db benchmarkПредлагаю сегодня поговорить о тестах производительности баз данных.
В чем собственно проблема
Мне нравятся бенчмарки. Я люблю сравнивать один подход с другим в своем коде. Стараюсь делать какие-то выводы из чужих бенчмарков. Короче бенчмарки это круто. Особенно для сложных, наукоемких или инфраструктурных вещей. Как писать бенчмарки на код все плюс-минус понимают, конечно там есть свои подводные камни о которых стоит рассказать отдельно, а вот как бенчмаркать базы данных большой вопрос. Особенно сложно становится, когда в наш уютный мир программирования влезает бизнес и маркетинг. Есть даже термин – benchmarketing. Когда компания берет своего конкурента, сравнивает свое творение с его и удивительным образом выигрывает это сравнение.
За примером ходить далеко не нужно. Вспомните когда timescale решили себя сравнить с clickhouse и как Тузик грелку его разорвали, а затем то же самое сделал clickhouse, но у же с timescale в своем ответном сравнении.
Я разделил ловушки на очевидные и неочевидные. Первые это ловушки такого рода, которые плюс-минус на поверхности, о них можно догадаться и спросить за них. А вот вторые ловушки очень опасные ибо они прячутся, чтобы их не нашли. Практически невозможно уличить в их использовании и каждая может и не несет большого воздействия, но в сумме дают те проценты превосходства, которые маркетологи и developer advocate используют, чтобы продать свою технологию.
Очевидные ловушки
- Отсутствие воспроизводимости Это, на мой взгляд, главная проблема бенчмарков баз данных ибо авторы умалчивают о деталях конфигурации железа, операционной системы и собственно базы данных. Что мы обычно видим: “мы использовали EC2 инстанс, версию баз данных такую-то, операционная система Ubuntu 22.04”. Но для воспроизводимости жизненно важно раскрывать всю информацию полностью. Если бы тесты были воспроизводимы, то не было бы противоречащих друг другу исследований.
- Отсутствие оптимизации Сравнения между базами данных имеют смысл только в том случае, если каждая из них была оптимизирована для предстоящей задачи. Были использованы правильные флаги компиляции, переменные окружения, флаги запуска. Если пренебречь всеми этими вещами полностью или частично для этой из систем, то сравнение уже будет не корректным.
- Специфичная настройка Существуют такие бенчмарки как tpc-h и tpc-c. Они стандартизированы и приближены к реальным сценариям использования. Кажется, что это отличная штука, которая помогает сравнивать базы данных независимо и дает нам транзитивность: если база данных
Апроизводительнее, чем база данныхВ, аВв свою очередь производительнееС, то сравниватьАиСникакого смысла нет. Хорошо, ведь так? Хорошо, если бы экспериментаторы не знали, что за данные и запросы будут использоваться в тесте. Иначе они могут перенастроить свою любимую базу данных строго на будущий тест. Взглянем на такой пример из работы [1].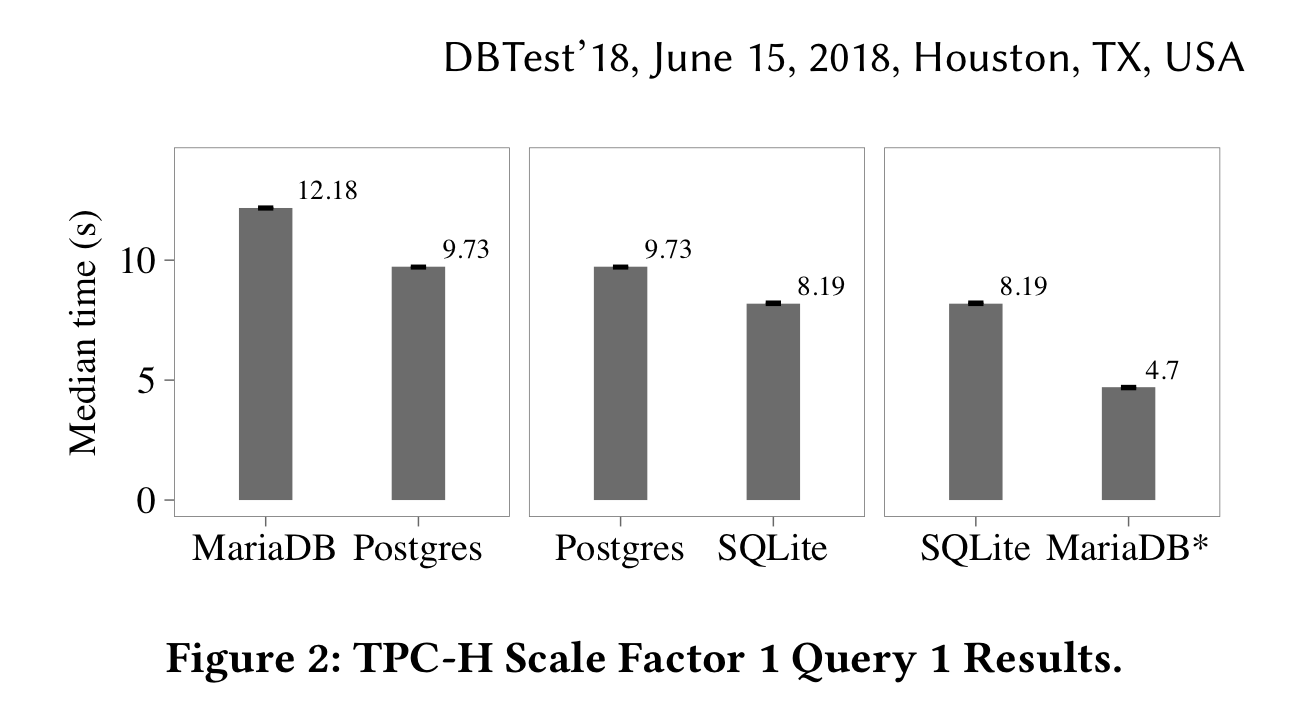
- Холодные/горячие запуски Производительность между холодным запуском и запуском после прогрева может отличаться катастрофически. Особенно если база данных ведет какую-то внутреннюю статистику для своего оптимизатора запросов или же переносит горячие данные с диска в память.
Неочевидные ловушки
Вот некоторые их тех, что пришли мне в голову:
- CPU Использовался ли turbo boost (если он есть) и был ли он включен/выключен явно?
- Операционная система Какие настройки C-States, планировщика процессов? Использовались ли huge pages?
- Сеть Запускать на одной машине и тестирующую и тестируемую систему не правильно, поэтому их разносят на разные машины. И тут в игру вступает сеть: как она была настроена, как утилизировалась и не стала ли она бутылочным горлышком?
Выводы
Выводов не будет. Я просто показал, как и где нас могут обманывать разработчики баз данных в своих рекламных статьях. Печально ли, что benchmarketing повсюду и мы не соревнуемся выявить лучшего из лучших? Да. По мне так лучше хотя бы знать об этом.
Ссылки
- Описательная статистика перформанс-распределений
- Fair Benchmarking in Database Performance Testing: Navigating Common Pitfalls
- Ускоряем железо и OS под PostgreSQL. Михал Жилин. Postgres Professional
Автор: Никита Галушко - Golang инженер, специализирующийся на производительности и распределённых системах. Больше технических разборов в Telegram: https://t.me/b1tw1se