Сравниваем Go драйверы к kafka
go kafkaМы в Lamoda плотно используем kafka. Такая активная работа не могла обойтись без написания своего врапера над каким-то из драйвров. Необходимо это для упрощения API, скрытие некоторых сложностей, покрытие метриками и т.п. Текущая обертка была построена на sarama и sarama-cluster, но время идет, создаются новые библиотеки, sarama-cluster уже не поддерживается и возник вопрос с переходом на что-то другое. Только вот для того, чтобы перейти на это “что-то другое” стоит сначала понять даст ли положительный эффект этот переход. Так и пришла идея сравнить производительность драйверов.
Дисклеймер! Данное сравнение ни в коем случае не претендует на какую-то научность или объективность. Весь код, который использовался для тестов расположен на GitHub.
Вы свободно можете склонировать его себе и проделать все тесты на своем окружении. Любые положительные изменения приветствуются через PR или issue.
Что сравниваем
Для Go есть три драйвера к kafka:
Последняя из них это C биндинги к librdkafka. Данная библиотека не участвует в сравнении, потому что CGo имеет достаточно много проблем с производительностью, которые могут не проявить себя в ходе простых тестов.
Как сравниваем
Мы определили что будем сравнивать. Теперь давайте определим как будем это делать. Я написал небольшую утилитку, которая конфигурируется при помощи флагов запуска, для проведения экспериментов. У нее есть два основных режима работы: consume и produce. Первый отвечает за тестирование потребления сообщений из kafka, второй за отправку сообщений.
В режиме consume мы в начале создаем топик со случайным названием и записываем в него определённое флагом records кол-во сообщений, где каждое сообщечение это цело число. Отсчет времени начинается после получения первого сообщения и заканчивается в момент, когда обработано все количество сообщений. Под обработкой здесь понимается простое сложение полученных чисел, дабы сконцентрироваться на работе с kafka.
В режиме produce мы в асинхронном виде пишем кол-во сообщений равных records. Отсчет времени начинается после создания producer-а и заканчивается после вызова метода Close, то есть после окончательного сброса всех внутренних очередей и буферов.
Результаты
Дано:
- kafka версии 3.0.0-0 развёрнутая в Docker на MacBook Air 2018 Intel Core i5 1.6GHz 16Gb;
- golang версии 1.17.
Consume
Потребление памяти (чем меньше тем лучше).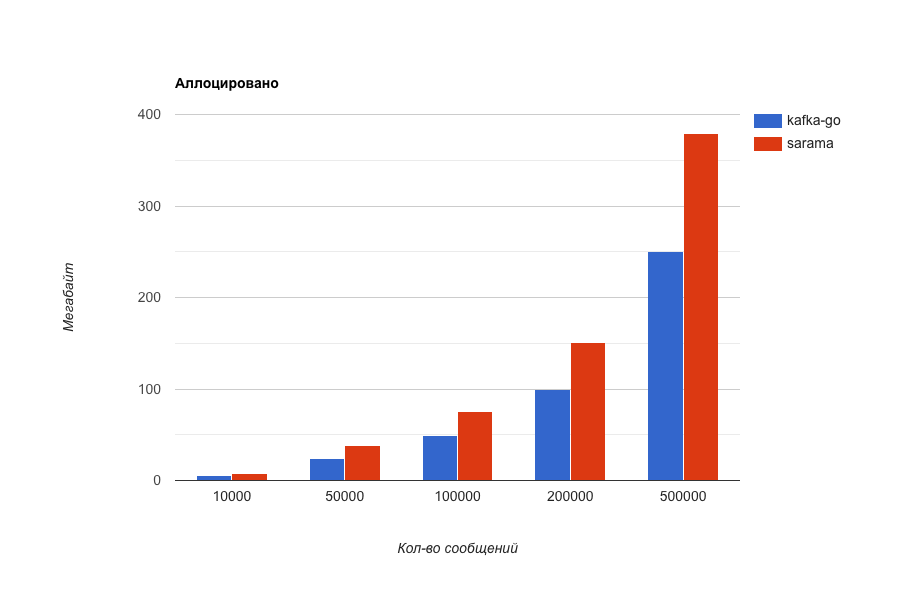
Время выполнения (чем меньше тем лучше).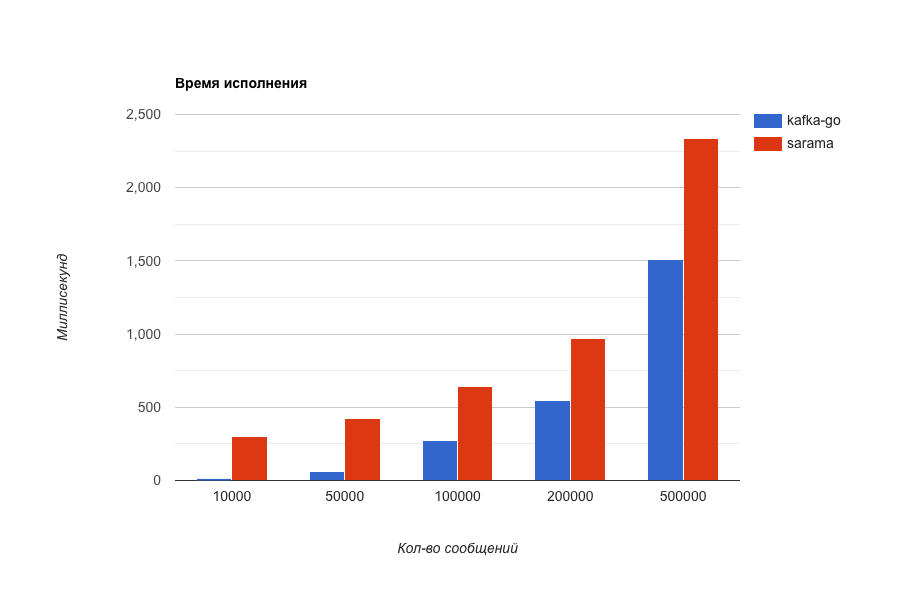
Produce
Потребление памяти (чем меньше тем лучше).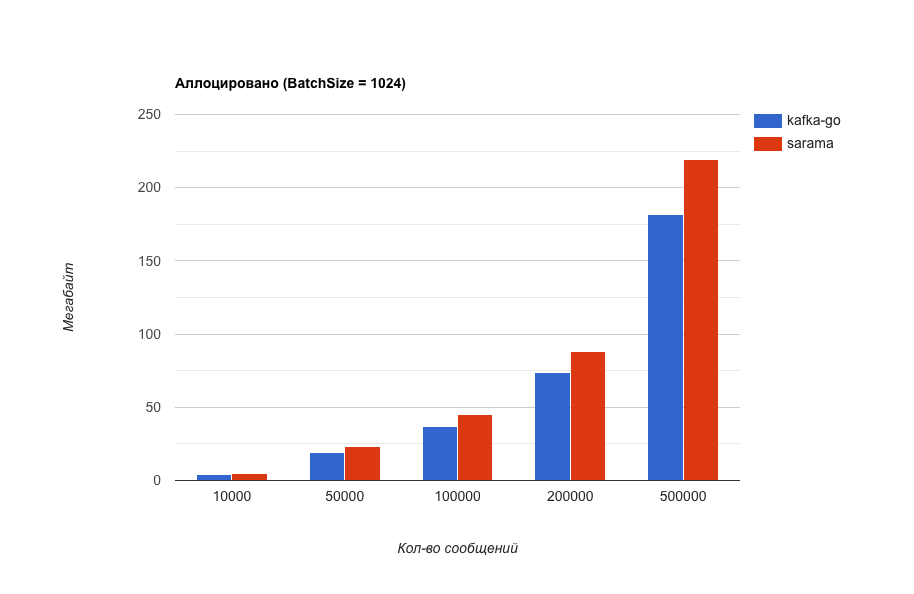
Время выполнения (чем меньше тем лучше).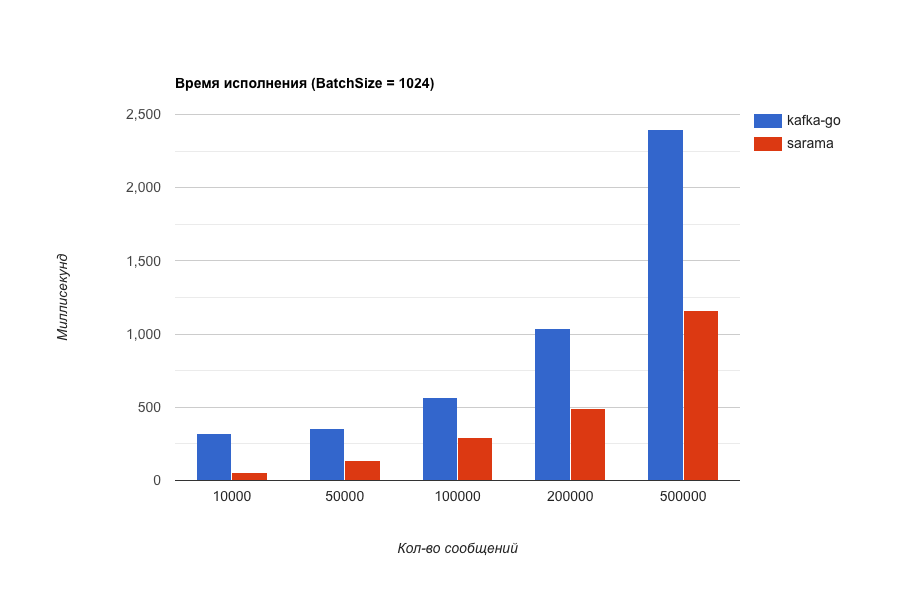
Что за BatchSize ? В kafka-go есть такая настройка, которая отвечает за размер блока сообщений, хранящийся в памяти перед отправкой в kafka. Эта настройка так сильно влияет на производительность, что я сделал еще один тест. (Для чистоты эксперимента в sarama имеется похожая настройка и ее значение изменялось в соответствии с тем, что выставлено в kafka-go).
Потребление памяти (чем меньше тем лучше).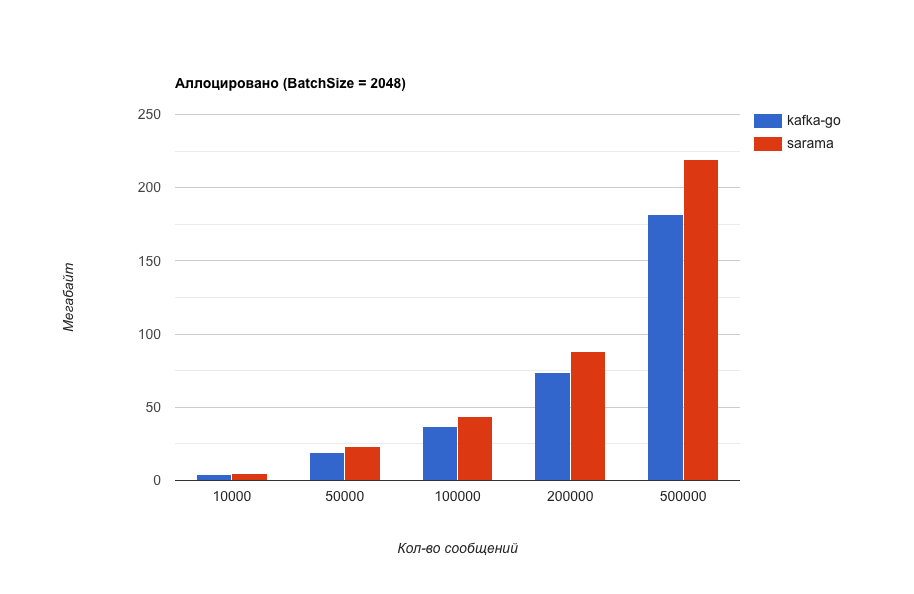
Время выполнения (чем меньше тем лучше).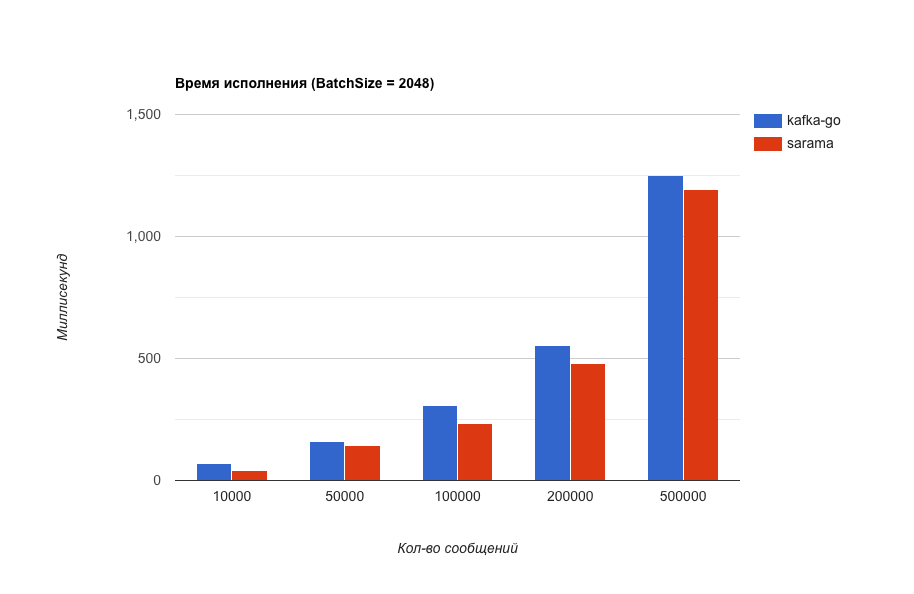
Выводы
kafka-go выглядит очень интересно и перспективно. Прямо сейчас в простом синтетическом consumer тесте она уделывает sarama как по потреблению памяти, так и по скорости работы. Вот только не может быть все так хорошо. Возможно я не досмотрел какие-то настройки, но в тесте на продюсинг сообщений только с достаточно большим внутренним буфером kafka-go смогла приблизиться к sarama. Что же касается второго подопытного, то это стабильная, проверенная временем и сообществом библиотека. С ней можно добиться хороших результатов без разбора хитросплетений настроек.
Учитывая все тесты я бы уже сейчас начал постепенный перевод сервисов на kafka-go.
P.S. Как только будут тесты с боевых сервисов использующих kafka, статья дополнится отдельным пунктом.
Автор: Никита Галушко - Golang инженер, специализирующийся на производительности и распределённых системах. Больше технических разборов в Telegram: https://t.me/b1tw1se