Поиск среди 10000 GitHub репозиториев на Postgres (используя только MacBook)
postgres переводПривет. Это вольный перевод интересной статьи Postgres regex search over 10,000 GitHub repositories (using only a Macbook). Перевод опубликован с согласия автора.
Так же можете подписаться на очередной канал разработчика в телеграмм.
В этой статье мы поделимся результатами своего эксперимента по использованию Postgres для индексирования и последующего поиска среди 10.000 GitHub репозиториев с использованием pg_trgm только на MacBook.
Это продолжение “Postgres Trigram search learnings”, в которой мы поделились некоторыми фишками и подводными камнями при использовании триграмм индексов в Postgres как альтернатива для гугловому Zoekt.
Мы поделились результатами, а так же точными шагами, чтобы вы могли воспроизвести результаты самостоятельно, если захотите.
TL;DR
Эта статья больше похожа на научную работу, нежели на очередную запись в блоге. Если интересны только выводы, то можешь обратиться к ним сразу.
Цели
Мы хотим получить эмпирические измерения о том, насколько Postgres подходит для поиска по документам с помощью regexp, в качестве альтернативы гугловому Zoekt. А конкретно:
- Сколько репозиториев можно проиндексировать на одном MacBook Pro 2019 года ?
- На сколько быстрым будет поиск по корпусу данных с помощью различных регулярных выражений ?
- Какая конфигурация Postgres 13 дает наилучший результат ?
- Какие посторонние эффекты нужно учитывать для того, чтобы рассматривать Postgres как бекенд поисковой системы на регулярных выражениях ?
- Какую схему базы данных лучше всего использовать ?
Железо
Все тесты запускаются на единственном MacBook Pro 2019 в конфигурации:
- 2.3 GHz 8-Core Intel Core i9
- 16 GB 2667 MHz DDR4 Во время выполнения тестов другие приложения почти не использовались, так что их эффектом на потребление CPU можно пренебречь и считать, что весь CPU/RAM были отданы для Postgres.
Корпус
Мы собрали списки 1000 лучших репозиториев с GitHub, отсортированных по количеству звездочек для каждого из следующих языков (всего получилось примерно 20500 репозиториев):
- C++, C#, CSS, Go, HTML, Java, JavaScript, MatLab, ObjC, Perl, PHP, Python, Ruby, Rust, Shell, Solidity, Swift, TypeScript, VB .NET и Zig. Клонирование всех 20500 репозиториев заняло примерно 14 часов с около 100Мб/с соединением до серверов GitHub.
Уменьшение размера датасета
Я обнаружил, что объем дискового пространства требуемого для git clone --depth 1 всего для 12148 репозиториев составляет примерно 412Гб, поэтому было принято решение использовать пару приемов для уменьшения размера набора данных примерно на 66%:
- Удаление директории
.gitдало снижение на 30% (412Гб -> 290Гб, для 12148 репозиториев) - Удаление файлов > 1Мб дало снижение еще на 51% (290Гб -> 142Гб, для 12148 репозиториев - GitHub, кстати, не индексирует файлы размером больше 384Кб)
Вставка данных
Вставка производилась конкурентно в Postgres со следующей схемой:
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE TABLE IF NOT EXISTS files (
id bigserial PRIMARY KEY,
contents text NOT NULL,
filepath text NOT NULL
);
Заняло это примерно 8 часов, а на диске Postgres занял 101Гб.
Создание индекса
Я трижды пытался проиндексировать набор данных используя GIN индекс:
CREATE INDEX IF NOT EXISTS files_contents_trgm_idx ON files USING GIN (contents gin_trgm_ops);
- В первый раз я поймал OOM после 11 с половиной часов индексирования. Это было связано с резким всплеском потребления памяти в самом конце индексирования. Это не было неожиданностью, так как использовалась достаточно агрессивная конфигурация Postgres с очень большим максимальным размером WAL.
- Во второй раз после 27 часов индексирования закончилось место на диске. Потребление дискового пространства также резко увеличилось к концу индексирования, то есть это не было постепенным увеличением потребления свободного места на SSD. Для этой попытки использовался прекрасный инструмент pgtune для уменьшения конфигурации Postgres из первой попытки:
shared_buffers = 4GB → 2560MB
effective_cache_size = 12GB → 7680MB
maintenance_work_mem = 16GB → 1280MB
default_statistics_target = 100 → 500
work_mem = 5242kB → 16MB
min_wal_size = 50GB → 4GB
max_wal_size = 4GB → 16GB
max_parallel_workers_per_gather = 8 → 4
max_parallel_maintenance_workers = 8 → 4
- В третий и последний раз, датасет был обрезан на половину и индексирование заняло примерно 22 часа. А конкретно была удалена половина файлов (с 19441820 файлов / 178Гб до 9720910 файлов / 82Гб). Конфигурация Postgres была аналогична той, что использовалась во второй попытке.
Потребление памяти
В первой попытке, контейнер с Postgres использовал целых 12Гб (если верить docker stats):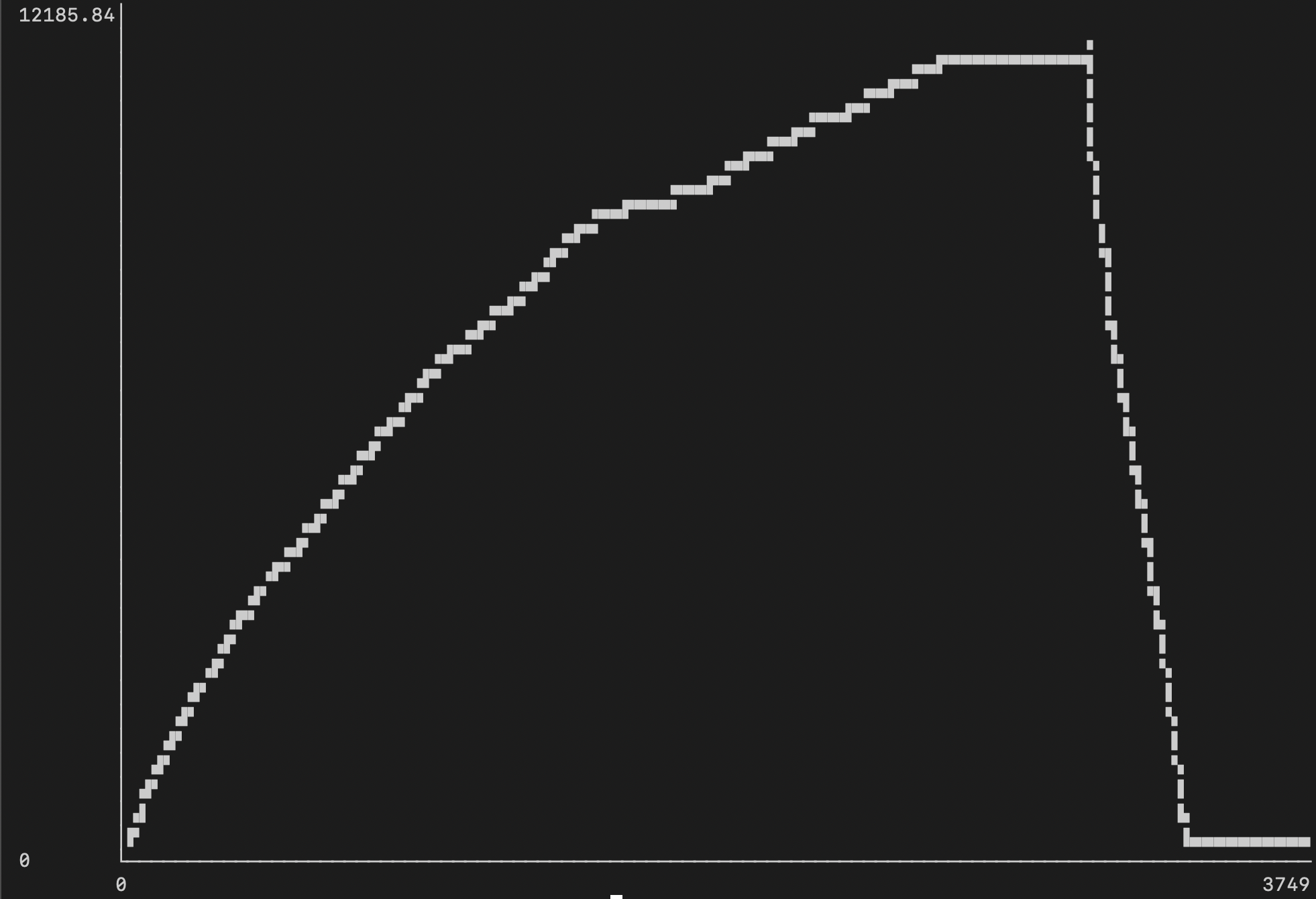
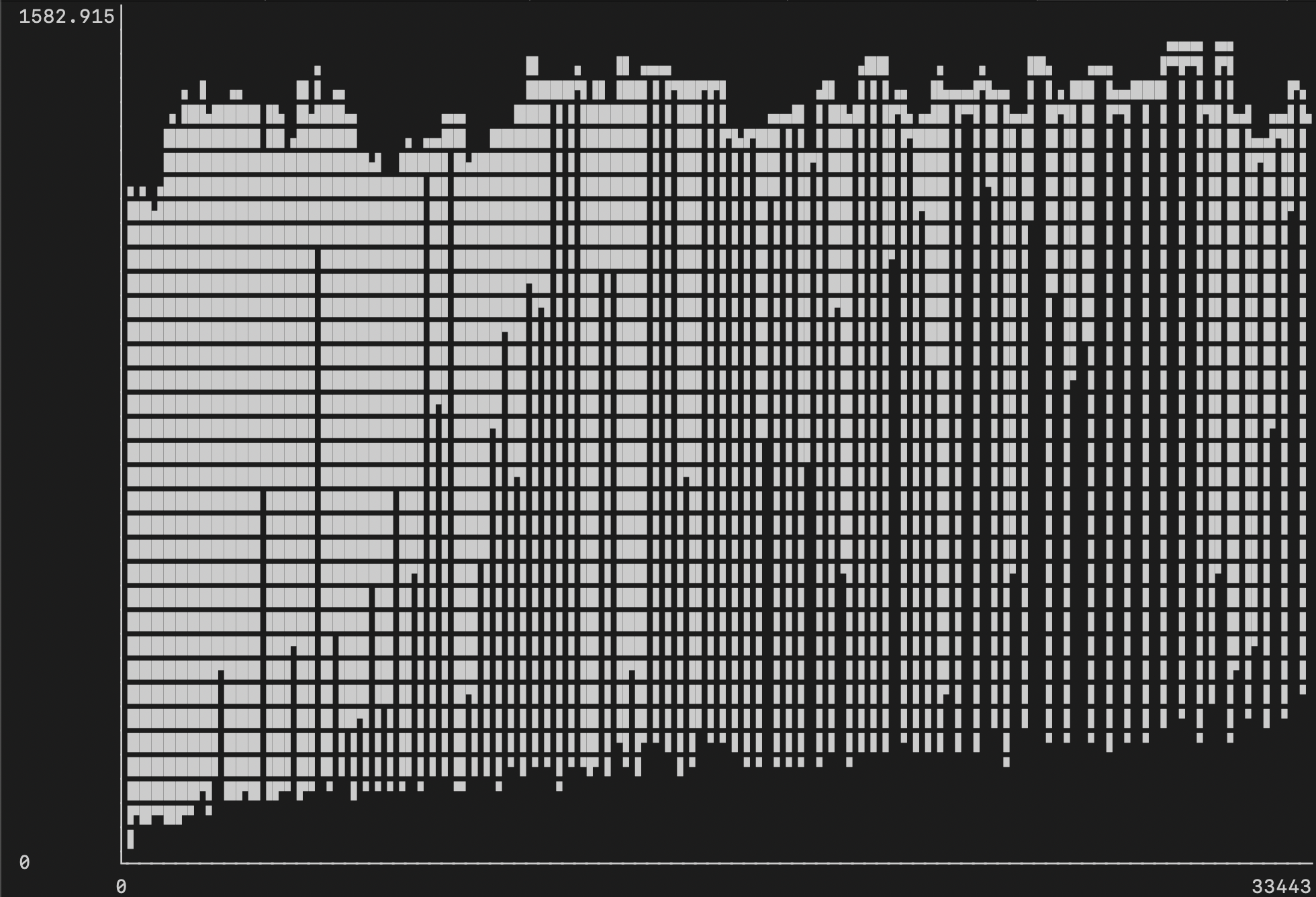
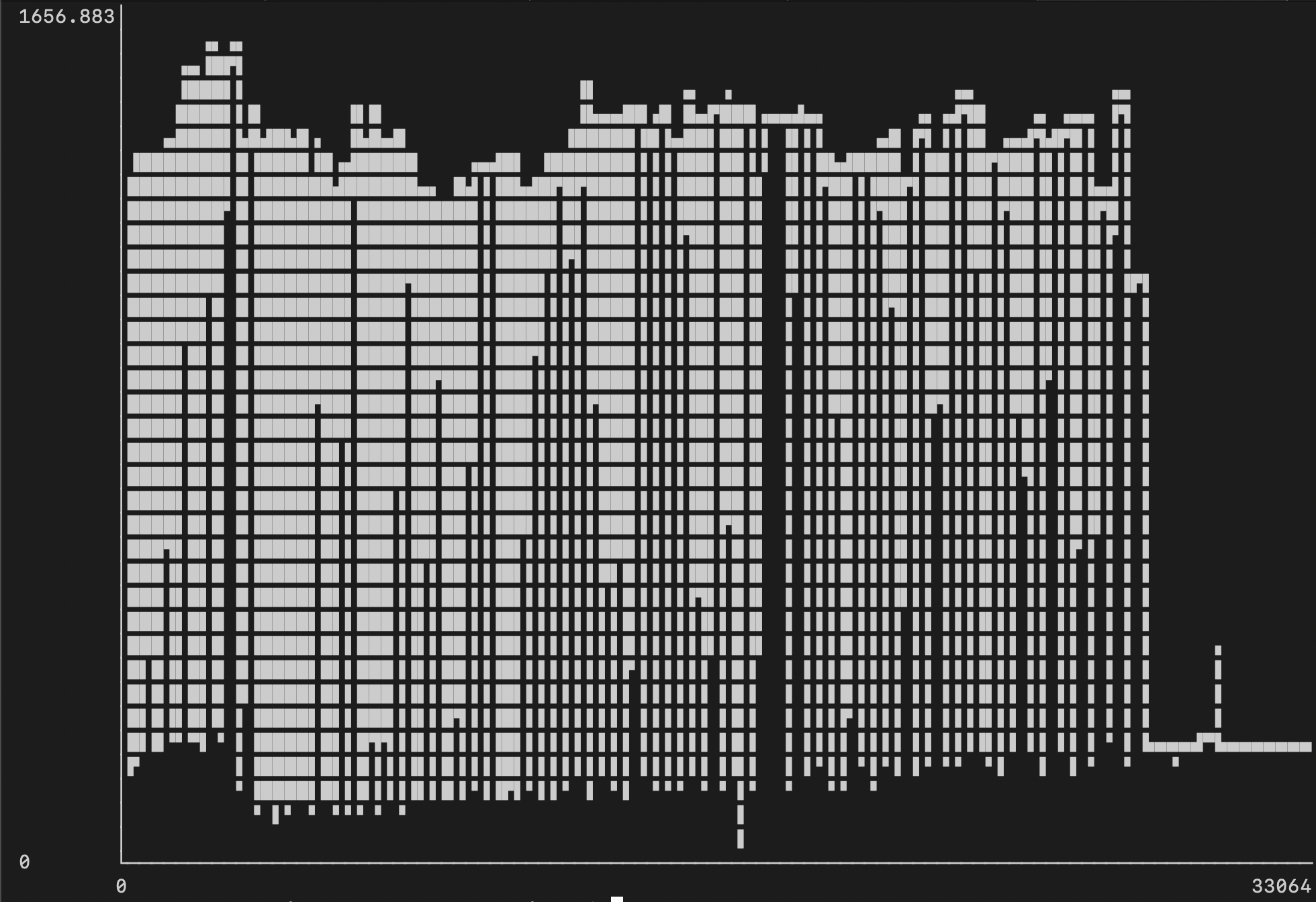
Во второй и третьей попытке использование памяти сильно упало (примерно до 1.6Гб):
Потребление CPU
Построение GIN индекса в Postgres похоже однопоточно (по крайней мере при индексировании одной таблицы, несколько таблиц будут протестированы позже).
В первой попытке использования CPU не превышало 156% (одно + половина виртуального ядра CPU):

Во второй попытке потребление CPU в среднем было 150-200%:
В третьей попытке потребление CPU было примерно таким же и составляло 150-200%, с небольшим всплеском до 350% к концу:
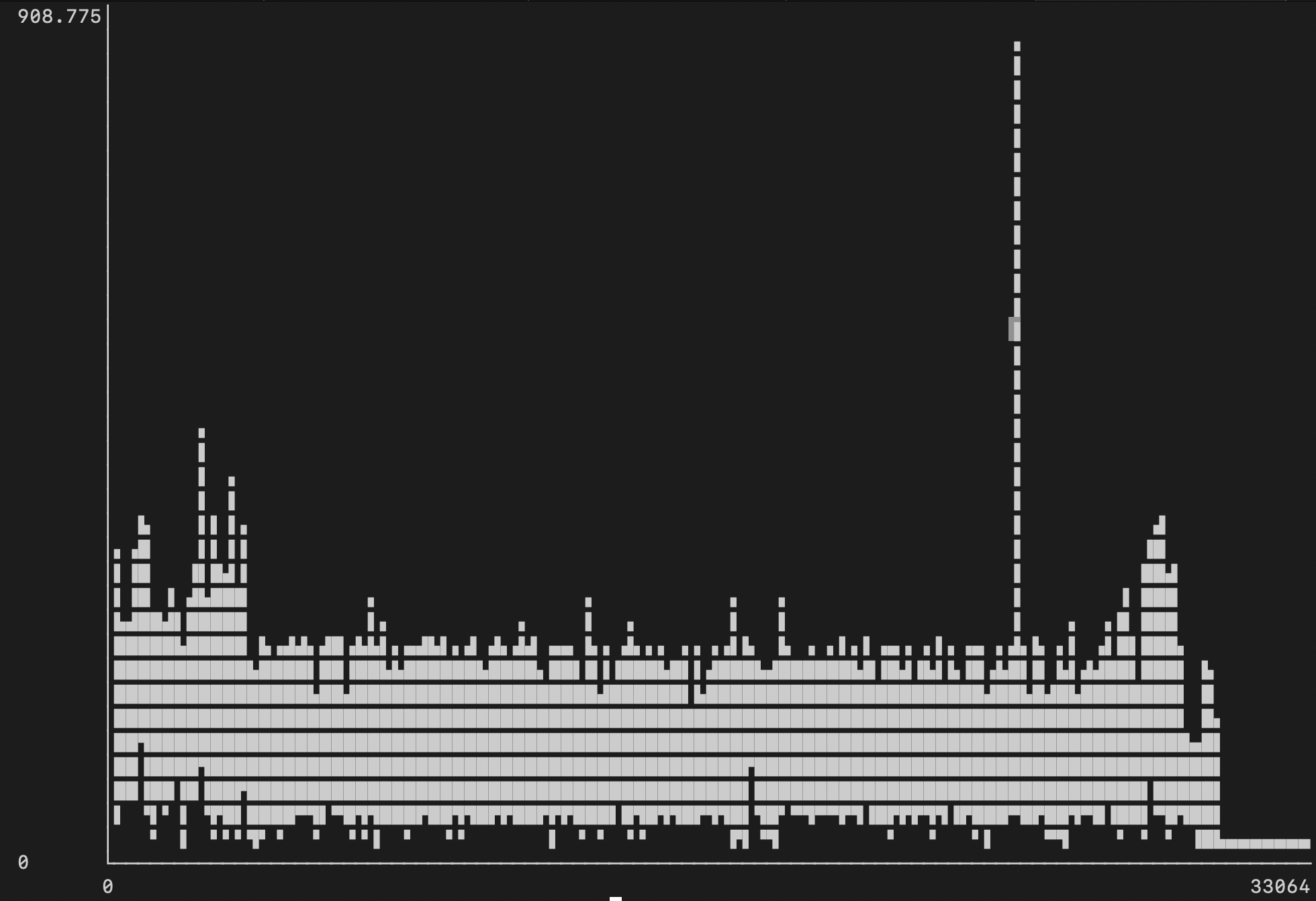
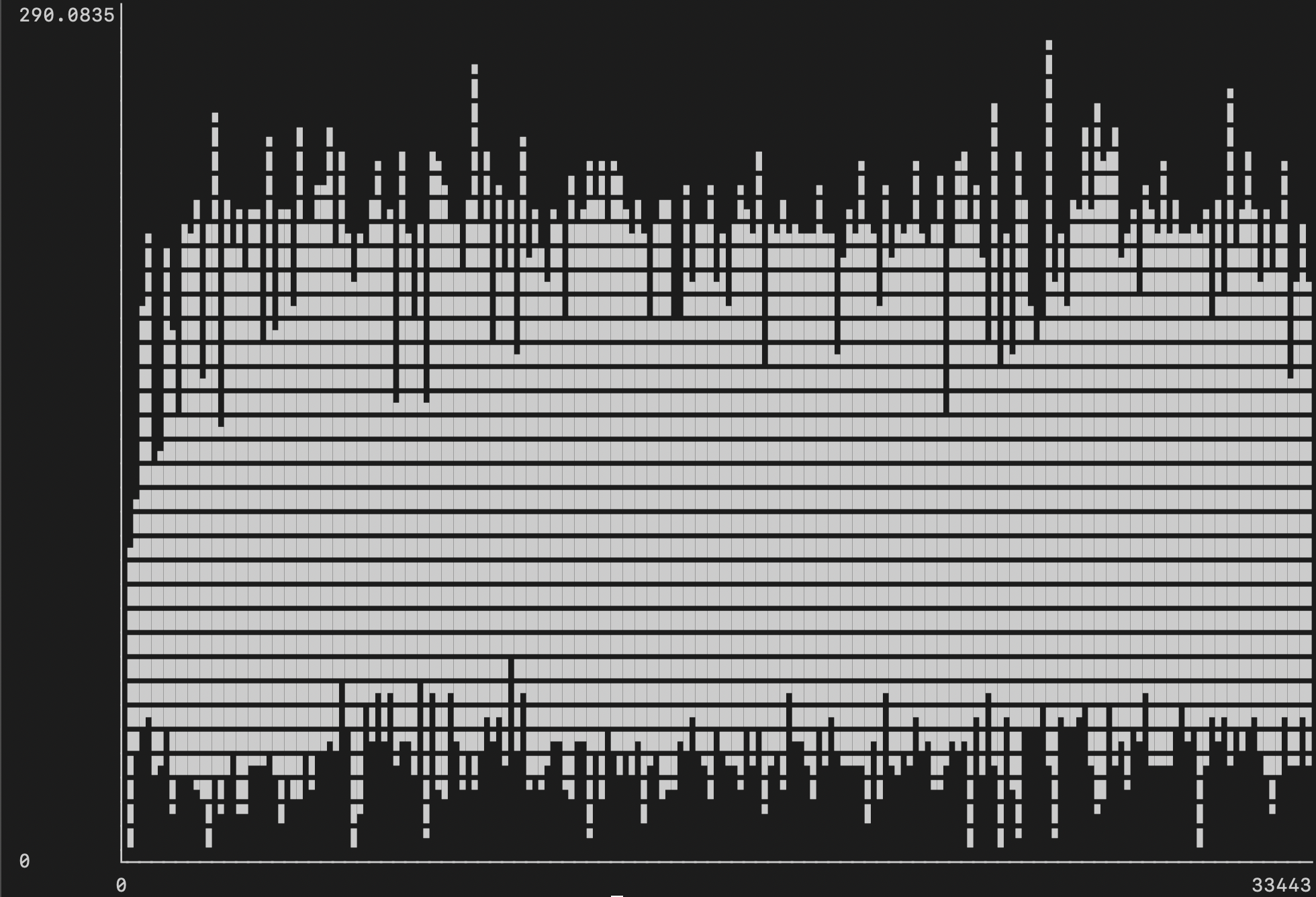
IO
Операции ввода-вывода для диска в процессе индексирования варьировались около 250Мб/с для чтения (голубой цвет) и записи (красный). Бенчмарки диска установленного в тестовый MacBook показывают, что он способен достичь скорости в примерно 860Мб/с на чтение/запись с <5% утилизацией CPU.
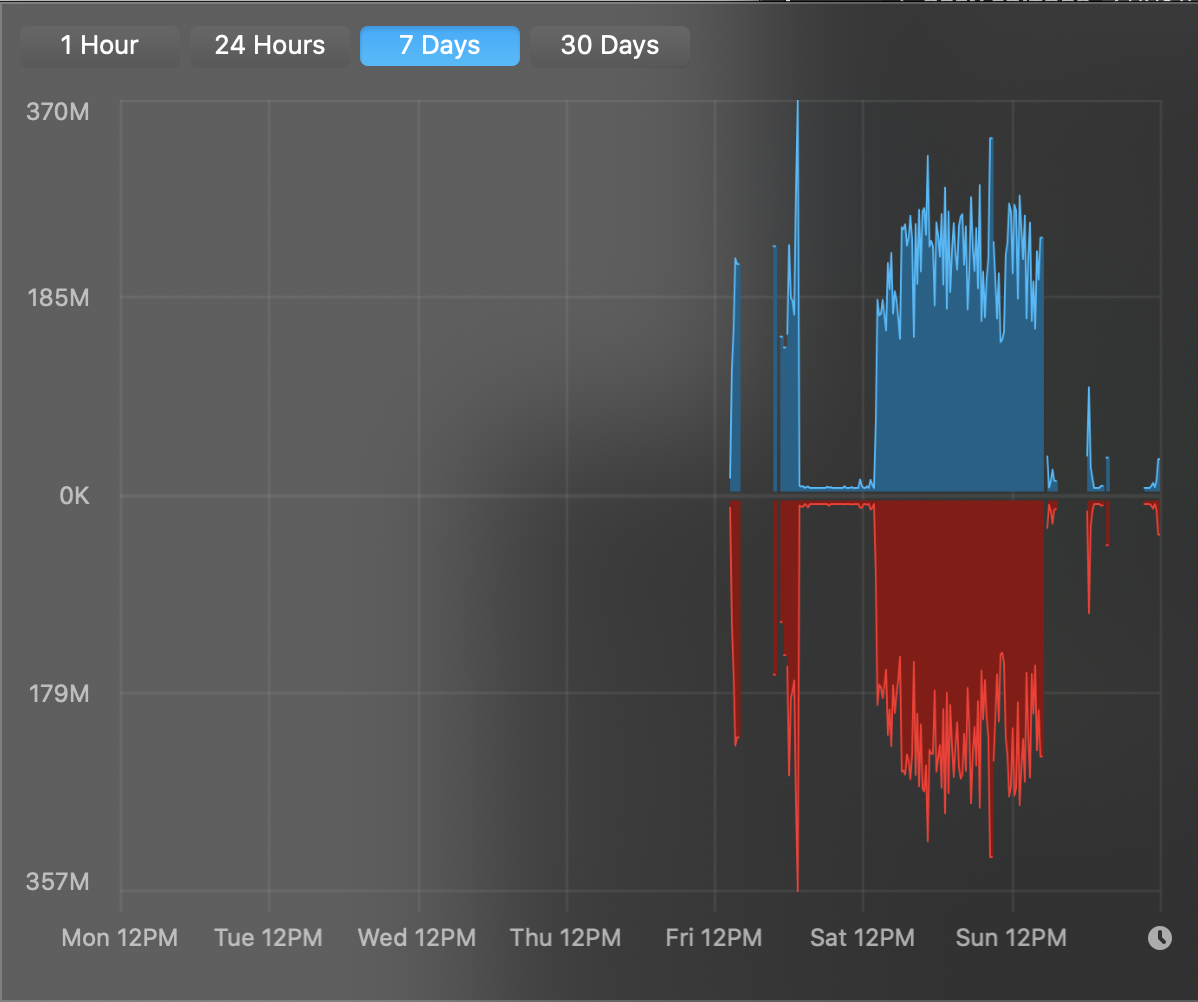
Примечание: Postgres вне контейнера показывает лучшую производительность при индексировании.
Дисковое пространство
База данных содержит 9720910 файлов общий размер которых 82.07Гб.
postgres=# select count(filepath) from files;
count
---------
9720910
(1 row)
postgres=# select SUM(octet_length(contents)) from files;
sum
-------------
88123563320
(1 row)
До индексирования Postgres занимал 54Гб:
$ du -sh .postgres/
54G .postgres/
После CREATE INDEX:
$ du -sh .postgres/
73G .postgres/
Таким образом, размер индекса для 82Гб текста составляет 19Гб (или 23% от объема данных).
Время запуска базы данных
С эксплуатационной точки зрения стоит отметить, что при штатном завершении работы Postgres, время его запуска практически моментально: Postgres сразу начинает принимать соединения и загружает индекс по мере его использования. В противном случае на запуск потребуется около 10 минут, так как при старте происходит процесс автоматического восстановления.
Запросы
В общей сложности мы выполнили 19936 поисковых запросов к индексу. Мы выбрали запросы, которые, по нашим ожиданиям, дают достаточно разное покрытие триграммного индекса (то есть запросы, триграммы которых с большей или меньшей вероятностью встречаются во многих файлах):
| Запрос | Совпадения # файлов в датасете |
|---|---|
| var | unknown (2000000+) |
| error | 1,479,452 |
| 123456789 | 59,841 |
| fmt.Error | 127,895 |
| fmt.Println | 22,876 |
| bytes.Buffer | 34,554 |
| fmt.Print.* | 37,319 |
| ac8ac5d63b66b83b90ce41a2d4061635 | 0 |
| d97f1d3ff91543[e-f]49.8b07517548877 | 0 |
Производительность запросов
В общей сложности мы выполнили 19 936 поисковых запросов к базе данных (линейно, не параллельно), которые завершились за следующее время:
| Временной промежуток | Процент запросов | Количество запросов |
|---|---|---|
| до 50 мс | 30% | 5933 |
| до 250 мс | 41% | 8088 |
| до 500 мс | 52% | 10275 |
| до 750 мс | 63% | 12473 |
| до 1 с | 68% | 13481 |
| до 1.5 с | 74% | 14697 |
| до 3 с | 79% | 15706 |
| до 25 с | 79% | 15708 |
| до 30 с | 99% | 19788 |
Реальная производительность vs. планировщик
Приведенный ниже график отражает, что 79% запросов выполнялись менее чем за 3 секунды (ось Y в миллисекундах), в то время как планировщик запросов Postgres планировал их выполнение за 100-250 миллисекунд (ось X):

Если мы расширим график таким образом, чтобы в него помещались все запросы, то увидим, насколько оставшиеся 21% запросов выбиваются от остальных (обратите внимание, что небольшой блок точек в левом нижнем углу представляет собой ту же диаграмму, показанную выше):

Потребление CPU/RAM
Следующие графики показывают:
- верхний — время запроса в миллисекундах
- средний — процент использования ЦП (например, 801% означает, что используется 8 из 16 виртуальных ядер)
- нижний — потребление памяти в мегабайтах

Из этого можно сделать следующие выводы:
- Значительное увеличение использования ресурсов к концу — это когда мы начали выполнять запросы без
LIMIT. - Использование CPU не превышает 138%, до всплеска в конце.
- Потребление памяти не превышает 42Мб, до всплеска в конце.
Есть подозрение, что pg_trgm является однопоточным в пределах одной таблицы, но также предполагаем, что лучшего параллелизма (и следовательно лучших результатов) можно добиться при партиционировании (разбиением данных на несколько таблиц).
Исследование медленных запросов
Если построить график зависимости количества повторных проверок индекса (ось X) от времени выполнения (ось Y), то можно увидеть, что одним из значимых аспектов замедления выполнения запроса является большее количество повторных проверок индекса:
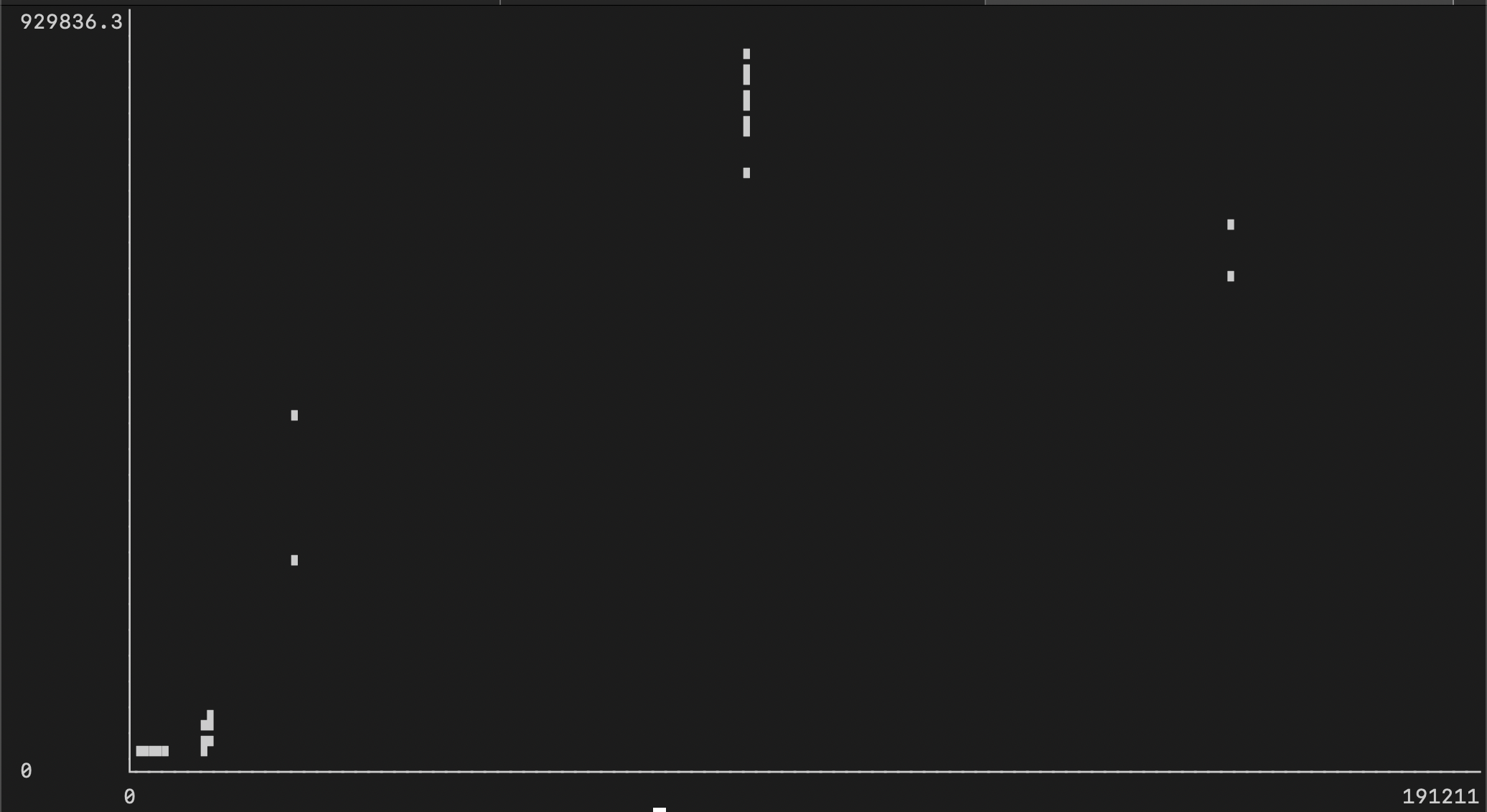
И если мы взглянем на EXPLAIN ANALYZE одного из таких запросов, то сможем подтвердить, что Parallel Bitmap Heap Scan работает медленно из-за Rows Removed by Index Recheck.
Партиционирование
Разделение на несколько небольших таблиц кажется очевидным подходом к тому, чтобы заставить pg_trgm использовать несколько ядер процессора. Мы попробовали это сделать, взяв тот же набор данных и разделив его на 200 таблиц, и обнаружили многочисленные преимущества.
№1: Инкрементальное индексирование
Весь прогресс индексирования не будет потерян, если в какой-то момент оно упадет или будет остановлено, как это случилось с нами дважды ранее.
№2: Параллельное индексирование
В отличии от нашего первого подхода, который показал, что при построении индекса использовались всего 1.5-2 виртуальных ядра CPU, то с несколькими таблицами мы смогли утилизировать 8-9 ядер CPU:
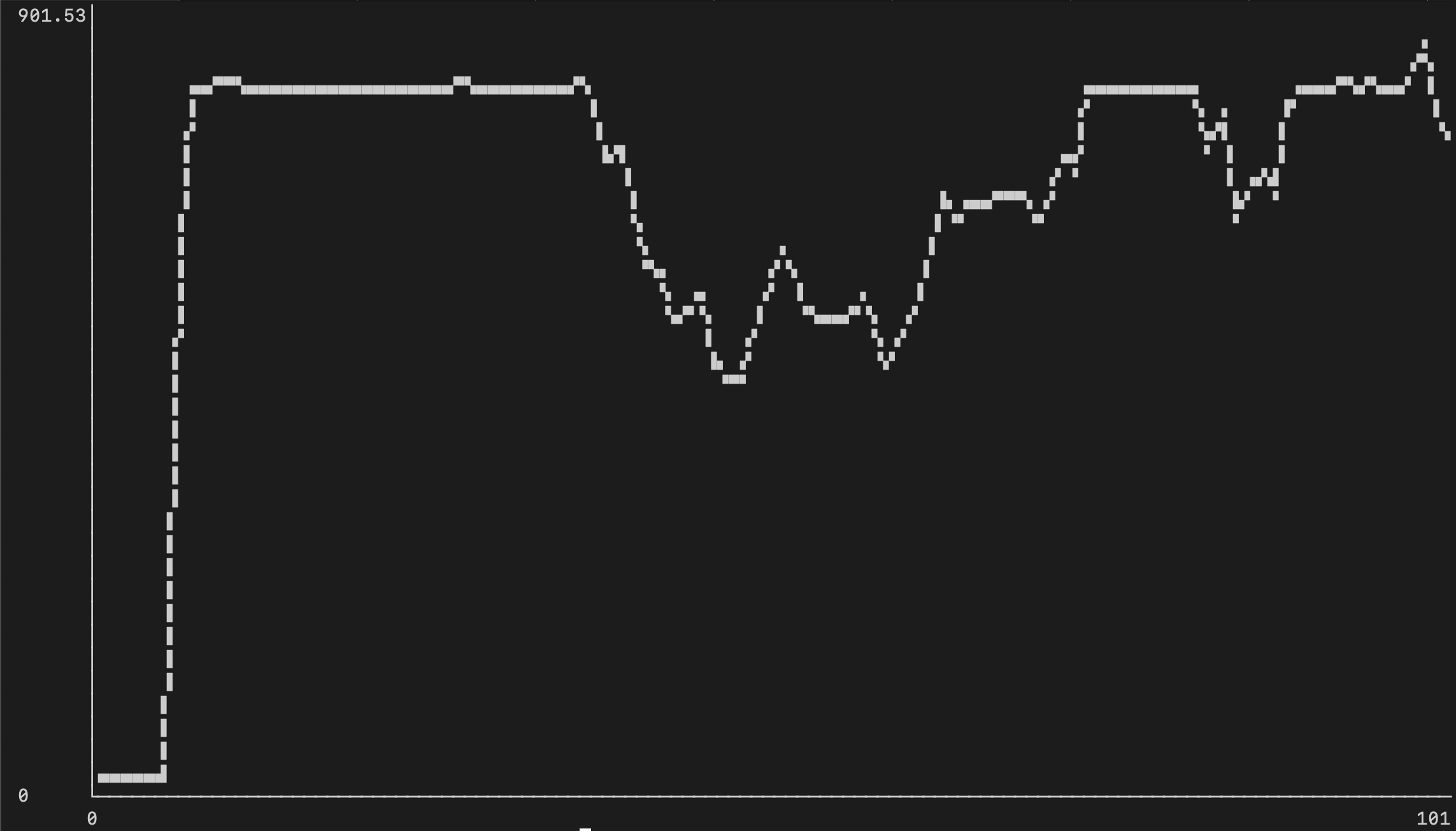
№3: Индексирование на 84% быстрее
В отличии от первого подхода, индексирование в котором занимало 22 часа, параллельное индексирование завершилось всего за 3 час 27 минут.
№4: Индексирование потребляет на 69% меньше RAM
В подходе с одной таблицей мы видели, что пиковое значение потребление памяти составляло 12Гб. С такой же конфигурацией Postgres, мы можем рассчитывать на пиковое значение потребления памяти всего в 3.7Гб:
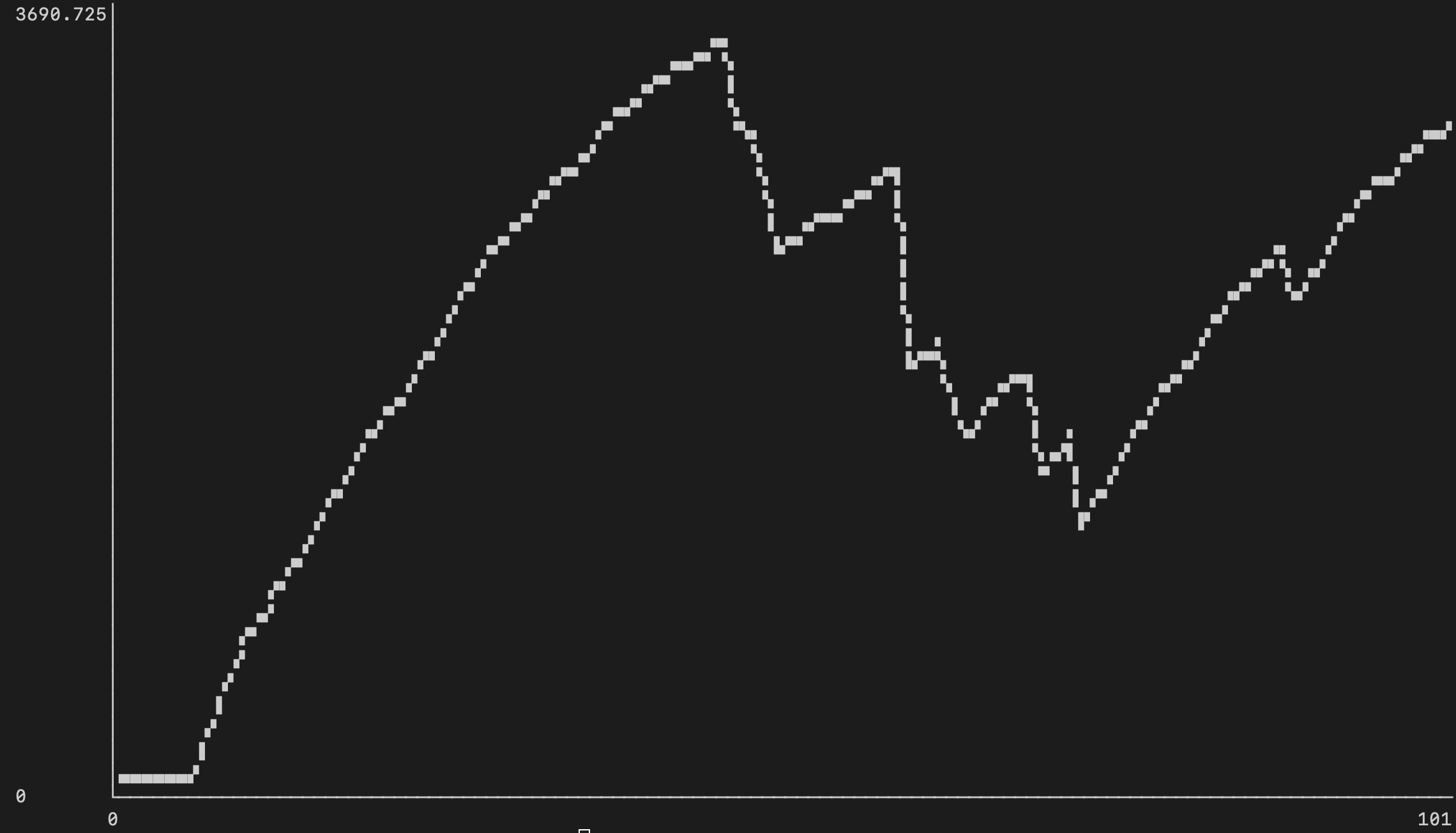
№5: Параллельная обработка запросов
Ранее мы наблюдали загрузку процессора всего на 138% (1.3 виртуальных ядра CPU), а с разделением таблиц мы видим загрузку процессора во время запросов на 1600% (16 виртуальных ядер CPU), что показывает, что мы выполняем работу полностью параллельно:

Аналогичным образом дело обстоит и с потреблением памяти. Среднее значение потребления памяти увеличилось до 380Мб, в отличии от 42Мб в подходе с одной таблицей:

№6: Производительность запросов
Мы повторно выполнили тот же набор поисковых запросов, но меньшее количество раз (350 запросов вместо 19.9 тыс., что, по нашему мнению, является достаточно представительной выборкой). Как мы можем видеть ниже, разделение таблиц в целом привело к улучшению времени выполнения запросов на 200-300% для более тяжелых запросов, которые раньше занимали 20-30 секунд, а теперь занимают всего 7-15 секунд благодаря параллельному выполнению запросов (верхний график - до, нижний - после, оба в миллисекундах):

Мы также сгруппировали запросы на основе LIMIT, указанного в запросе, и распределили их по временным интервалам (“сколько запросов завершилось менее чем за 50 мс?”) - сравнение этих двух показателей дает понять, что менее сложные запросы и/или запросы с меньшим количеством результатов пострадали незначительно, в то время как более крупные запросы получили существенный прирост в производительности:
| Изменение | Ограничение по результатам | Бакет | Запросов в бакете до | Запросов в бакете после |
|---|---|---|---|---|
| -33% | 10 | <50мс | 33% | 0% |
| +13% | 10 | <250мс | 44% | 57% |
| +33% | 10 | <1с | 77% | 100% |
| -29% | 100 | <100мс | 29% | 0% |
| +20% | 100 | <500мс | 50% | 70% |
| +19% | 100 | <10с | 80% | 99% |
| -12% | 1000 | <250мс | 12% | 0% |
| -13% | 1000 | <2.5с | 77% | 64% |
| +23% | 1000 | <20s | 77% | 100% |
| +4% | none | <20с | 0% | 4% |
| +18% | none | <60с | 0% | 18% |
Запросы с `LIMIT 10`
| Временной бакет | Процент от запросов (до) | Процент от запросов (после разделения) |
|---|---|---|
| 50мс | 33.00% (2999 из 9004) | 0% (0 из 100) |
| 100мс | 33.00% (2999 из 9004) | 1.00% (1 из 100) |
| 250мс | 44.00% (3999 из 9004) | 57.00% (57 из 100) |
| 500мс | 55.00% (4999 из 9004) | 79.00% (79 из 100) |
| 1000мс | 77.00% (6998 из 9004) | 80.00% (80 из 100) |
| 2500мс | 77.00% (7003 из 9004) | 80.00% (80 из 100) |
| 5000мс | 77.00% (7004 из 9004) | 80.00% (80 из 100) |
| 10000мс | 77.00% (7004 из 9004) | 100.00% (100 из 100) |
| 20000мс | 77.00% (7004 из 9004) | 100.00% (100 из 100) |
| 30000мс | 99.00% (8985 из 9004) | 100.00% (100 из 100) |
| 40000мс | 99.00% (9003 из 9004) | 100.00% (100 из 100) |
| 50000мс | 100.00% (9004 из 9004) | 100.00% (100 из 100) |
| 60000мс | 100.00% (9004 из 9004) | 100.00% (100 из 100) |
Запросы с `LIMIT 100`
| Временной бакет | Процент от запросов (до) | Процент от запросов (после разделения) |
|---|---|---|
| 50мс | 29.00% (2934 из 10000) | 0% (0 из 100) |
| 100мс | 29.00% (2978 из 10000) | 0% (0 из 100) |
| 250мс | 39.00% (3975 из 10000) | 31.00% (31 из 100) |
| 500мс | 50.00% (5000 из 10000) | 70.00% (70 из 100) |
| 1000мс | 59.00% (5984 из 10000) | 79.00% (79 из 100) |
| 2500мс | 79.00% (7996 из 10000) | 80.00% (80 из 100) |
| 5000мс | 80.00% (8000 из 10000) | 80.00% (80 из 100) |
| 10000мс | 80.00% (8000 из 10000) | 99.00% (99 из 100) |
| 20000мс | 80.00% (8000 из 10000) | 100.00% (100 из 100) |
| 30000мс | 99.00% (9999 из 10000) | 100.00% (100 из 100) |
| 40000мс | 100.00% (10000 из 10000) | 100.00% (100 из 100) |
| 50000мс | 100.00% (10000 из 10000) | 100.00% (100 из 100) |
| 60000мс | 100.00% (10000 из 10000) | 100.00% (100 из 100) |
Запросы с `LIMIT 1000`
| Временной бакет | Процент от запросов (до) | Процент от запросов (после разделения) |
|---|---|---|
| 50мс | 0% (0 из 904) | 0% (0 из 100) |
| 100мс | 0% (1 из 904) | 0% (0 из 100) |
| 250мс | 12.00% (114 из 904) | 0% (0 из 100) |
| 500мс | 30.00% (276 из 904) | 21.00% (21 из 100) |
| 1000мс | 55.00% (499 из 904) | 41.00% (41 из 100) |
| 2500мс | 77.00% (700 из 904) | 64.00% (64 из 100) |
| 5000мс | 77.00% (704 из 904) | 77.00% (77 из 100) |
| 10000мс | 77.00% (704 из 904) | 98.00% (98 из 100) |
| 20000мс | 77.00% (704 из 904) | 100.00% (100 из 100) |
| 30000мс | 88.00% (804 из 904) | 100.00% (100 из 100) |
| 40000мс | 99.00% (901 из 904) | 100.00% (100 из 100) |
| 50000мс | 99.00% (903 из 904) | 100.00% (100 из 100) |
| 60000мс | 100.00% (904 из 904) | 100.00% (100 из 100) |
Запросы без `LIMIT`
| Временной бакет | Процент от запросов (до) | Процент от запросов (после разделения) |
|---|---|---|
| 50мс | 0% (0 из 28) | 0% (0 из 50) |
| 100мс | 0% (0 из 28) | 0% (0 из 50) |
| 250мс | 0% (0 из 28) | 0% (0 из 50) |
| 500мс | 0% (0 из 28) | 0% (0 из 50) |
| 1000мс | 0% (0 из 28) | 0% (0 из 50) |
| 2500мс | 0% (0 из 28) | 0% (0 из 50) |
| 5000мс | 0% (0 из 28) | 0% (0 из 50) |
| 10000мс | 0% (0 из 28) | 0% (0 из 50) |
| 20000мс | 0% (0 из 28) | 4.00% (2 из 50) |
| 30000мс | 0% (0 из 28) | 16.00% (8 из 50) |
| 40000мс | 0% (0 из 28) | 16.00% (8 из 50) |
| 50000мс | 0% (0 из 28) | 18.00% (9 из 50) |
| 60000мс | 0% (0 из 28) | 18.00% (9 из 50) |
Docker vs. нативный Postgres
Сначала мы не думали о влиянии производительности при запуске Postgres в Docker. Этот вопрос был поднят Thorsten Ball, как потенциальный источник разницы в производительности IO операций.
Все тесты выше были произведены на запущенном в Docker Postgres с использованием драйвера osxfs, а не экспериментального драйвера FUSE gRPC.
Мы дополнительно прогнали те же тесты на собственном сервере Postgres и обнаружили следующие ключевые изменения.
Потребление CPU/RAM
Потребление CPU и памяти было похожим на то, что мы наблюдали с Postgres в Docker.
Индексирование стало на 88% быстрее
Разбиение одной большой таблицы на несколько маленьких происходило следующим образом:
CREATE TABLE files_000 AS SELECT * FROM files WHERE id > 0 AND id < 50000;
CREATE TABLE files_001 AS SELECT * FROM files WHERE id > 50000 AND id < 100000;
...
Процесс разбиения был куда быстрее в нативно запущенном Postgres. На построение каждой таблицы уходило от 2 до 8 секунд, тогда как при запуске в Docker на это уходило 20-40 секунд.
Параллельное создание триграмм индексов
CREATE INDEX IF NOT EXISTS files_000_contents_trgm_idx ON files USING GIN (contents gin_trgm_ops);
также было быстрым, всего 23 минуты вместо примерно 3 часов в Docker.
Скорость обработки запросов увеличилась на 12-99%
Мы запустили те же 350 запросов с нашего прошлого теста и обнаружили несколько существенных улучшений:
- Запросы, которые ранее выполнялись очень медленно, улучшились на ~12%. Вероятно, это связано с операциями ввода-вывода, необходимыми при взаимодействии с 200 отдельными таблицами.
- Для средних по времени выполнения запросов, прирост составил примерно 5%.
- Запросы, которые ранее были очень быстрыми (вероятнее всего поиск осуществлялся по одной-двум таблицам), улучшились на 16-99%.
Исчерпывающие детали сравнения (негативные изменения - это хорошо)
| Изменение | Временной бакет | Запросы в бакете до | Запросы в бакете после |
|---|---|---|---|
| 0% | 500s | 350 из 350 | 350 из 350 |
| -12% | 100с | 309 из 350 | 350 из 350 |
| -12% | 50с | 309 из 350 | 350 из 350 |
| -12% | 40с | 308 из 350 | 350 из 350 |
| -12% | 30с | 308 из 350 | 349 из 350 |
| -7% | 25с | 307 из 350 | 330 из 350 |
| -7% | 25с | 307 из 350 | 330 из 350 |
| -8% | 20с | 302 из 350 | 330 из 350 |
| -8% | 20с | 302 из 350 | 330 из 350 |
| -5% | 10с | 297 из 350 | 311 из 350 |
| -26% | 5с | 237 из 350 | 319 из 350 |
| -7% | 2500мс | 224 из 350 | 240 из 350 |
| -9% | 2000мс | 219 из 350 | 240 из 350 |
| -9% | 1500мс | 219 из 350 | 240 из 350 |
| -16% | 1000мс | 200 из 350 | 237 из 350 |
| -14% | 750мс | 190 из 350 | 221 из 350 |
| -23% | 500мс | 170 из 350 | 220 из 350 |
| -59% | 250мс | 88 из 350 | 217 из 350 |
| -99% | 100мс | 1 из 350 | 168 из 350 |
| -99% | 50мс | 1 из 350 | 168 из 350 |
Выводы
Мы считаем, что наиболее важными являются следующие выводы:
- Директория
.git, даже с клонированием--depth=1, составляет 30% от размера репозитория на диске (по крайней мере, в 10000 лучших репозиториев GitHub). - Файлы более 1Мб (часто бинарный файлы) составляют другие 51% от объема данных на диске.
- Используя только MacBook, возможно построить GIN индексы Postgres по 10000 репозиториев GitHub и выполнять большинство разумных запросов менее чем за 5 секунд и, конечно, гораздо быстрее при использовании более мощного железа.
pg_trgmвыполняет индексирование и поиск однопоточной, если не разделить данные на несколько таблиц.- По умолчанию, Postgres сжимает колонки с типом
text, что в результате приводит к уменьшение размера на 23%. pg_trgmиндексы занимают около 26% размера данных на диске. Таким образом, если индексируется 1Гб необработанного текста, то можно ожидать, что Postgres потребует для хранения данных примерно 827Мб, а для индекса около 279Мб.- Разделять данные на несколько таблиц при использовании
pg_trgmэто однозначно то, что следует делать. Такой подход позволяет уменьшить время на построение индекса (в нашем случае с 22 часов до 4). - Bind mount довольная медленная технология за пределами хост-окружения Linux.
Автор: Никита Галушко - Golang инженер, специализирующийся на производительности и распределённых системах. Больше технических разборов в Telegram: https://t.me/b1tw1se